Twenty Years of Bitext
“Oh, yes, everything’s right on schedule, Fred”
Peter Brown & Bob Mercer
In the late eighties and early nineties, Robert Mercer, Peter Brown, and their research colleagues at IBM applied statistical approaches from speech recognition to the problem of machine translation (MT), which is the task of getting computers to automatically translate human languages. Their work launched an entire field of research that has culminated today in good quality commercial automatic translation services like Microsoft Translator and Google Translate. Soon after this early work, they left the field for Wall Street, where they helped build one of the world’s most successful hedge funds, Renaissance Technologies, which they now run. In October of 2013, Bob and Peter gave an invited talk and Q&A session at the EMNLP workshop Twenty Years of Bitext, which celebrated their pioneering scientific work and took stock of the progress that had been made in the meantime. The talk was entitled, “Oh, yes, everything’s right on schedule, Fred”, in reference to a story they told about starting their work on statistical MT while their boss, the late Fred Jelinek, was away. Also in attendance were Stephen and Vincent Della Pietra. Below is an annotated transcript of their portion of the workshop.

Noah Smith
All right. Welcome back. I’m Noah Smith, one of the co-organizers, and I have a couple of announcements before we start the next session. The first is that I think that we misstated earlier about the time to come back, so after the lunch break the workshop will start again at three, but if you are presenting a poster you need to get here at ten till three to set up your poster, I think out in the corridor, and there’s a sign telling the order that you should set up. Check in with us at ten until three to make sure you know what to do.
I thought long and hard about how to do this introduction. I’m going to use an analogy. A couple of years ago I gave a talk at a journalism conference and I had this experience of realizing that our field had a creepy fascination with the work that was being done by journalists and they really had no idea. So when I introduce — when I started talking about what natural language processing does, I told journalists that their work was actually being secretly gathered after it was published, and then painstakingly read over and over again, and manually annotated by people obsessed with every little detail and all of the words and building parse trees and things like that. I think they were freaked out and I haven’t been invited back.
Now here we are. This is a really strange experience, so I wasn’t there in 1993. Philipp was in high school; I was in … I won’t even say, but what we have from that time is set of papers that are evidence for something going on that was clearly very amazing. When I was rattling off to my students, what came out of this research group at this time, I mentioned things like maxent models which gave us in the long run discriminative feature-based learning which is now central to natural language processing and machine translation, the whole data-driven driven philosophy of using data to build language understanding systems. Brown clustering [PDF] — yes, that’s a person, Brown! I don’t know if Peter knows that they call it Brown clustering, but —
Peter Brown
Mercer Clustering.
Noah Smith
— this is still one of the most important things that we use these days. If you want to see tweets, Brown clusters of words from Twitter, you can browse those on our web page. Word sense disambiguation results and then of course statistical machine translation. Is there anything that we use now that wasn’t invented in this group? Did you guys do the Brown Corpus too? [laughter]
Anyway, all this stuff came out right around the same time and it’s all very mysterious to us now, but those of us who want to do great research in this field, and want to build groups that do great research, we have this strong sense, based on the evidence, that something really interesting was happening back then. I just want to reassure you guys (I know you came with maybe some trepidation) that whatever you say is going to be a great interest, and we’ll be poring over your words very carefully. Hopefully not [crosstalk], but for a long time to come.
It’s my great pleasure to welcome Bob Mercer and Peter Brown, and I also want to mention that Stephen and Vincent Della Pietra are also here in the audience. This will be a talk for about an hour and then we’ll have a panel moderated graciously by Philip Resnik until lunch time. So welcome Bob and Peter.

Bob Mercer
Thank you Noah. When we got Noah’s invitation to speak at this workshop, our first thought was, “What could we possibly talk about?” We left IBM Research twenty years ago, and we’ve completely ignored the natural language processing in the world since then, and regrettably, we can’t talk at all about what we actually do these days. We decided to just reminisce. I’m going to start with a few words about how I came to be writing computer programs in the IBM speech recognition group and then I’ll turn it over to Peter to talk a bit about translation.

The ENIAC was the first general purpose electronic digital computer. Its name is an acronym for Electronic Numerical Integrator and Computer. Here’s what it looked like. It was invented by J. Presper Eckert and John Mauchly and it weighed about thirty tons. It had two hundred decimal digits of storage organized as twenty signed ten-digit integers and could do three hundred fifty multiplications per second. As you can probably figure out, each digit weighed about three hundred pounds. It was originally intended for computing artillery tables, but was soon drafted by John von Neumann for H-bomb calculations. It was built at the University of Pennsylvania and accepted by the US Army Ordnance Corps in July of 1946. That date is important to me because that’s the month I was born.
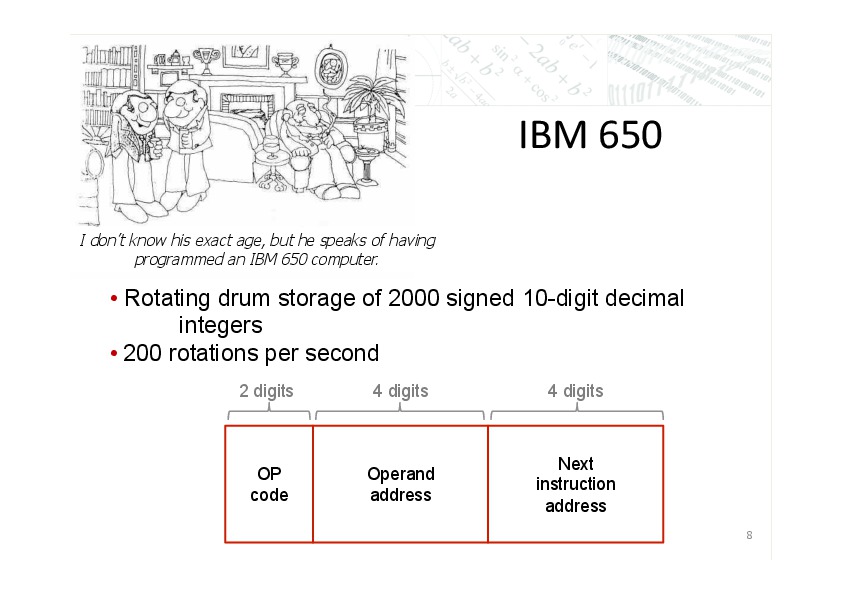
Now I’ve always been fascinated with computers, but I didn’t learn anything about them until ten years later when my dad explained to me how the IBM 650 worked. The 650 had a memory with two thousand signed ten digit integers stored in a cylindrical drum that spun around its axis two hundred times a second. When interpreted as an instruction, these integers had an op code explaining what operation to carry out, the address of the operand would participate in the operation, and a second address for where on the drum to find the next instruction. Each of these addresses was four digits long, which is obviously necessary if you want to be able to address any one of the two thousand places on the drum, and this left two digits for the op code.
Now if your current instruction finished too soon, you might have to wait a few microseconds so that the appropriate integer would roll under the read head and you could figure out what to do next. But if your instruction took a little bit too long, so that the address with the next instruction had just passed under the read head by the time you were ready for it, you would have to wait another five milliseconds for the drum to roll all the way around before you could figure out what to do next. I didn’t have a computer manual, and I really didn’t have any idea what it meant to write a computer program or even what the instructions were, but I spent all my time thinking about that problem of coordinating everything so that the next instruction was available just when you needed it, you wouldn’t have to wait for the drum and go around again. When I was older my dad brought home a Burroughs B5000 Algol manual. I wrote a lot of Algol programs that I kept in a big notebook that I carried around with me, but it’s very unlikely that any of them actually worked because I never had a computer to run them on. I didn’t get to use a real computer until after high school.

During the summer, after my senior year, I spent three weeks representing New Mexico at the National Youth Science Camp, learning to program in Fortran, and working on an IBM 1620 that IBM had donated to the camp. That machine had forty thousand decimal digits of memory and could do fifty ten-digit multiplications a second. When the camp ended I enrolled at the University of New Mexico in Albuquerque to study math, physics, and chemistry. In those days there were no Computer Science courses at UNM, but I got a job at the nearby Kirtland Air Force Base weapons lab writing Fortran programs for a CDC 6600. Now the 6600 was truly a super computer in its day. It had 256,000 60-bit words of memory and could compute more than a million 60-bit multiplies per second.

The jump from the 1620 to the 6600 was really astonishing to me, and while I was at the weapons lab I heard stories that a guy named Dan Slotnick was building a computer called the ILLIAC IV at the University of Illinois. It was said that when the ILLIAC IV was turned on it would double the world’s computing power. I learned a lot of fascinating things at the weapons lab, but perhaps the most important thing that I learned was that I really loved everything about computers. I loved the solitude of the computer lab late at night. I loved the air conditioned smell of the place. I loved the sound of the disks whirring and the printers clacking. I loved thumbing through listings. I even loved Hollerith cards. So when I left UNM and the weapons lab I forsook the graduate study of mathematical logic that I’d been planning and headed off to the U of I to study computer science and to help with the ILLIAC IV.

Now in case some of you have never seen a Hollerith card, here’s a picture of Herman Hollerith. He invented a punched card like this one that was used in tabulating the 1890 census. In 1911 the Tabulating Machine Company that he founded merged with three other firms to form the Computing Tabulating Recording Company, which had its name changed to IBM by Thomas J. Watson in 1924. Over the years, the Hollerith card transformed into this.

After I finished my Ph.D., I applied for job at IBM research even though I had a very dim opinion about IBM computers, having seen the vast difference between the 1620 and the 6600. But I was very impressed when I visited the Watson Research Center, both by the place and by the people working there. They offered me a job working on a compiler to produce provably correct code. I accepted their offer in the spring of 1972, but by the time I showed up for duty that fall, the project had been canceled. The head of the computer science department told me to take a few weeks to look around for a group that I’d like to work in. So I did, I spoke to a number of people in the then newly-forming speech recognition group, which was intellectually headed by Fred Jelinek and Lalit Bahl, a couple of information theorists.
I felt immediately with their noisy channel formulation of the speech recognition problem was the correct way to look at things, so I signed up. I’d scarcely unpacked my bags, so to speak, when an old guy named John Cocke stopped by to talk to me. Although I didn’t know it at the time, John was a very famous guy at IBM. He wanted to talk to me because I’d been involved in with the Illiac IV, and in 1958, while Slotnick was at IBM, he and John had written a paper discussing an architect similar to the Illiac IV architecture. I suppose John had an office, but although I had many, many conversations with him during my years at IBM, I never saw him in his office. As far as I can recall, I never even knew where his office was. He just wondered around talking to people.

Here’s a picture of John. John’s the one on the right. The fellow on the left is John Backus, who invented FORTRAN. This picture was taken sometime in the late 50s or early 60s, but to be honest that’s just my guess based on the fact that Backus looks so young, and the two of them were both at IBM research during those years. I show it because this is what John looked like when I first saw him in 1972, and it’s pretty much how he looked the last time I saw him in the late 90s. He always wore a coat and tie, and he was usually smoking a cigarette, and he always had cigarette burns on his coat or his shirt or his tie or his trousers. John was very enthusiastic about both speech recognition and machine translation. I think that Peter will talk a little bit more about him later on.

Here’s something we jocularly called the fundamental equation of speech recognition at ICASSP in 1981. As I’m sure all of you very well know, this is just an application of Bayes’ Rule. One problem associated with using it in speech recognition or in machine translation is you have to be able to compute the probability of w, a probabilistic characterization of the sequences of words that make up the English language. This requires a statistical model of English. Our idea was to take a bunch of English text and model it as the output of some finite state machine. But we didn’t have any computer-readable text. Today, I gather it’s easy to assemble a few billion computer readable documents, but back then there wasn’t much around. We set as our goal natural English sentences with a vocabulary of a thousand words. This size lay well beyond what was typical of the finite state languages that were popular in speech recognition at the time, and yet still within our ability to handle it.

Our first thought was to use IBM manuals, of which there were quite a few, and many of these were quickly and easily available to us in computer readable-form. We realized right away that we had to abandon this plan — the vocabulary was too large. We also felt that it would be difficult to pass most of it off as English. [laughter]

Then we learned that the Voice of America was broadcasting its radio programs in something called Basic English, with a vocabulary of only 850 words, so that the oppressed people of the world could understand what they were being told without the bother of really having to learn English. It sounded ideal, but we immediately ran into two problems. First, the promoters of Basic English ignored the conjugation of verbs, the declensions of nouns, adjectives, and adverbs when reckoning the size of its vocabulary. Second, at least for the Voice of America, Basic English is really something of an ideal to strive for rather than a master to obey. When totting up the size of the vocabulary, they don’t count personal names, place names, or words that they figure everyone will know anyway. The Voice of America broadcast did not at all cleave to an 850-word vocabulary. Again we had to abandon this area because the vocabulary was too large.

Our next idea was to hire a couple of typists to create computer-readable text ourselves from children’s books: Hardy Boys, Nancy Drew, Tom Sawyer, Lassie, stuff like that. These books are typically a few tens of thousands words long. Pretty soon our diligent typists had produced a million or so words. But again, we had to abandon the project, because the vocabulary was too large.

[laughter] Then our colleague, Fred Damerau from the linguistics department at the lab, told us that the US patent office had computerized their patent archives in the field of laser technology. At his suggestion, we acquired this collection of text. The subject matter was remarkably narrow, as one might expect, and we were able to assemble a collection of about a million and a half words of text in sentences that had a vocabulary of only a thousand words, so at last we had a success.

Now, there’s no data like more data, and over the years our ambitions grew beyond the limited thousand-word vocabulary. We found a number of other large computer-readable corpora, let me run through them quickly. First up is Dick Garwin’s correspondence. Dick Garwin, who created the first H-Bomb design, was an IBM Fellow and Physics Professor at Columbia. He kept a stable of secretaries at the research center busy with his voluminous correspondence on a very wide range of technical and scientific topics. He kept all of his correspondence in computer-readable form, and allowed us to use it for language modeling. As I recall, this was a couple of million words. Next up is the Associated Press.

When Peter joined IBM in the early 80s, he negotiated with Verbex, his former employer, to give us their twenty million word collection of text for the Associated Press news wire. Then we learned that some oil company had a bunch of computer-readable text that they were willing to let us use for language modeling. But they were concerned about turning over complete documents; fortunately, we were able to convince them to allow us to collect a sorted list of all 11-gram snippets that appeared in their text.
Later we discovered that the Federal Register was maintained electronically. We negotiated a deal whereby Peter went down to Washington to do some work for the government, and in return they gave us access to all that text. I just don’t recall how big the federal registered data was, and since we’re no longer at IBM, we can’t really find out. The American Printing House for the Blind is an organization that produces Braille versions of novels and periodicals, and they gave us 60 million words.

The IBM deposition database is an interesting case of utility accidentally created by the government in spite of itself [laughter]. In 1969, at a time when the price of computing had fallen by 35% to 40% a year for the past several years — as, by the way, it has continued to do it from then until now — the US Department of Justice, on behalf of ill-served computer folk everywhere, filed an antitrust suit against IBM. 13 years later, it dawned on the Justice Department that their case was without merit, and so they dropped it. But in the meantime, IBM created an enormous operation in White Plains, New York to digitize all of the depositions that were created as part of this case. That’s a government jobs program.

In a gigantic room, hundreds of key punch operators worked keying onto Hollerith cards, the text of the various depositions that IBM had provided the government’s lawyers. I couldn’t find a picture of the White Plains operation; what I’m showing here is a picture of some people entering data for the 1940 US census. The White Plains operation looked more like this [laughter]. Or like this, or maybe even like this. It was really a gigantic thing.

By the time it came to our attention, the deposition database had about 100 million words.

John Cocke, who introduce us to this collection, always asked three questions to decide if a corpus had really broad coverage. Does it contain the word hacksaw? [laughter] Does it contain the word pickle? and does it contain some other word which unfortunately I forget. The IBM deposition corpus is the only one we had that could answer yes, yes, yes.

Finally, this brings us to the Canadian Hansards text, another collection we first learned about from John Cocke. At this point I’m going to turn the microphone over to Peter, who will take up more of the translation-specific topics. Here you go.
Peter Brown
Thank you Bob. Before I leave the topic of machine-readable corpora, I’d like to mention one thing about the oil company database that Bob conveniently omitted. One problem with taking all the 11-grams in sorted order was that they used up 11 times as much space as the original text. Now Bob had an ingenious way around this problem, he convinced the oil company to permit us to the use any technique we wanted to compress the data [laughter]. It turns out the 11-grams in the database are almost all unique, so it was quite a simple matter to compress the data by a factor of 11 [laughter], simply by putting the text back together again. Our interest in machine translation really began with John Cocke, who as Bob mentioned was truly a legendary figure at IBM research. John was an absolutely wonderful and absolutely brilliant man who wandered the halls of the Watson labs, pollinating ideas from one group to another. Then after work he would wonder from one bar to another doing the same thing. We knew this because it was not unusual to receive a late night call from John, who was holed up in the phone booth in his local tavern wanting to discuss some idea or another from the latest IEEE issue on information theory. Once after a session at a conference that John attended with Lalit Bahl in Boulder, Colorado, John suggested they go out for a drink, which quickly turned into many drinks at a series of bars. Lalit was completely amazed to find that each time they entered a new bar, someone would call out, “Hey, John, it’s so good to see you, it’s been so long since you were in Boulder, let’s have a drink”. John just loved people nearly as much he loved ideas.
Anyway, at some point in the 1980s, John was on a plane, and of course he struck up a conversation
with the guy next to him and then suggested they have a drink together. Before he knew it the guy
was telling John about the proceedings of the Canadian House of Parliament which were — and
probably still are — kept in computer-readable form in French and in English. When he got back to
the lab, John wandered over to our offices to tell us about all this text. We of course immediately
acquired the data and incorporated the English text into the language models we were using for
speech recognition and typing correction. Actually, since I mentioned typing correction, let me take
a little detour here to explain that. We realized that with a decent language model, it might be
possible to build a really bang-up spelling corrector. Freed from the need to avoid mistakes, a
typist should be able to type incredibly fast. Using the English side of the Canadian database,
with which we were working at the time, we built a program and it worked fantastically well,
cleaning up all kinds of sloppily-typed text.  At one point we were
demonstrating the program to the IBM brass, urging them to make it into a product, when a guy named
Dan Prener walked into the room. Now no matter
what we typed, it was converted into a least locally decent English. Dan saw this and asked to try
an experiment. He went up to the keyboard and with two fingers typed in random gibberish and out
came this sentence. “Politics costs Canada more than bear hunting” [laughter]. I guess that’s the
kind of thing that Canadian Parliamentarians were worried about in those days.
At one point we were
demonstrating the program to the IBM brass, urging them to make it into a product, when a guy named
Dan Prener walked into the room. Now no matter
what we typed, it was converted into a least locally decent English. Dan saw this and asked to try
an experiment. He went up to the keyboard and with two fingers typed in random gibberish and out
came this sentence. “Politics costs Canada more than bear hunting” [laughter]. I guess that’s the
kind of thing that Canadian Parliamentarians were worried about in those days.
Meanwhile, John Cocke kept after us to see if it might be possible to use the English and French text together to learn something about how translation works. Unfortunately, the head of our group, Fred Jelinek, was a bit of a task master, so we didn’t have any time for that. That is, until Fred took his annual summer vacation in Cape Cod. It was during Fred’s summer vacations that we entertained ourselves by trying out avant garde ideas. Every now and again, Jelinek would call in, and we’d report, “Oh, yes, everything’s right on schedule, Fred!” Then we’d go back to whatever far-fetched project we were actually working on.
Finally, in 1987 or 1988, we got around to looking at the French side of the Hansards data. The days in the French and the English were already aligned in the database for us. Using a straight-forward application of dynamic programming, with a model based on sentence lengths, we attempted to line up the French and English sentences, and that worked surprisingly well. Next we decided to see if we could extract translation probabilities from co-currence statistics, and that too worked out pretty well. We began to formulate what became the basic word alignment model.

At this point, Fred came back from the beach, carrying his wet blanket, but instead of reprimanding us for wasting so much time on translation, he was as excited as we were, and insisted that we write up our work. The result was a 1988 COLING paper, “A Statistical Approach to Machine [sic] Translation”, a paper that we wrote with John Cocke, Fred Jelinek, Stephen and Vincent Della Pietra, who are here today, and Paul Roossin. The cold water that we’d expecting from Fred instead came from some anonymous COLING reviewer who wrote,

“The validity of statistical information theoretic approach to machine translation has indeed been recognized as the authors mentioned by Weaver as early as 1949, and was universally recognized as mistaken by 1950 [laughter]. The crude force of computers is not science; the paper is simply beyond the scope of COLING.”

You can see from what Bob was saying earlier, that in 1950 computers were somewhere between the 20 signed 10-digit integer stage and the 2,000 signed 10-digit integer stage. So, actually it would have been more reasonable, if instead of “the crude force of computers is not a science”, the reviewer had written “the force of crude computers is not science” [laughter]. Amazingly, despite this rather dismissive review, the paper was accepted for presentation at COLING. I wonder what COLING reviews look like for papers that get rejected [laughter].
Over the next year Bob and the Della Pietra brothers and I worked out the basic alignment model and realized that we could estimate its parameters with the EM algorithm. After we got that straightened out, we published a much better paper in 1990 [PDF], adapting the source channel setup familiar to us from speech recognition. After estimating the parameters of a primitive translation model, we turned to our attention to decoding, where, unlike in speech, sentences cannot be decoded in left-to-right order. Nonetheless, the basic idea of a source model, a channel model, a stack search, and an estimate of the cost to produce those words not yet accounted for, were all the same.

Back then we did most of our work on
IBM RT workstations. They were probably twenty times
slower than the laptops and iPads people are using here today, and also twenty times as expensive
and fifty times as heavy. Each IBM research staff member had one of these things, and we did all of
our coding in PL .8, a wonderful language that never went
anywhere. The workstations were new products and so we all suffered from various hardware problems
that the designers didn’t quite have worked out. That is, except for Bob. He did all of his work on
the antediluvian mainframe.  We all knew Bob’s workstation wasn’t
getting any use, so whenever one of ours broke, we’d just go into Bob’s office and swap out the
appropriate part from one in his machine [laughter]. Little by little, we replaced his keyboard,
his power supply, his screen, various memory chips, his mouse, and various other components.
We all knew Bob’s workstation wasn’t
getting any use, so whenever one of ours broke, we’d just go into Bob’s office and swap out the
appropriate part from one in his machine [laughter]. Little by little, we replaced his keyboard,
his power supply, his screen, various memory chips, his mouse, and various other components.
Then one day Bob decided it was time to get going on his workstation [laughter], but of course the power supply didn’t work, so the machine wouldn’t even power up. But using a technique that would serve him well, once he hit it big on Wall Street, he fixed it easily. “How’d you do it?”, I asked. “Oh, it wasn’t a problem”, he replied, “I just called service”. “Did you let them know that we replaced your entire machine with parts that don’t work?” “No”, he replied, “I just told them the machine didn’t seem to be functioning properly” [laughter].

Anyway, even when they were running, these machines were really slow. It used to take us 10 minutes to decode a 10-word sentence. Back then, IBM was not doing particularly well, and Abe Peled, the head of computer science, told us that he viewed the translation effort as a luxury, a luxury that we feared would be next on the chopping block; that is, unless we could bring in some outside money. So we were very excited to learn that DARPA was requesting proposals to work on language translation. Luckily for us, we had already developed a basic statistical model and were even beginning to obtain translation results. We submitted a proposal to DARPA, and along with Dragon Systems and Carnegie, were awarded a three year contract. We give a lot of credit to Charles Wayne at DARPA, who funded us, even though none of us could speak French, and we had no idea what those sentences we were translating meant.
As I’m sure most of you know, in order to get money from the government for research, you have to make a proposal for what you’re going to do. We always proposed to do during the next twelve months whatever it was we’d just finished doing in the previous twelve months [laughter]. Although this guaranteed that we would meet our goals, Charles demanded more. He insisted we write everything down so as to disseminate the techniques and ideas throughout the natural language community. We just wanted to push ahead, but Charles had the whip hand.
It is because of Charles’ firmness that we wrote a paper in 1993 on the mathematics of parameter estimation in machine translation [PDF]. In retrospect, this was a good thing as it forced us to stop and think carefully about what we were doing. For example, our grasp of model deficiency came from attempting to describe the difference between Model 4 and Model 5 in that paper. Charles also held a number of workshops to encourage the translation community to share ideas. In our opinion, these were far less valuable than paper writing.
From today’s vantage point, it’s probably difficult to imagine what those meetings were like. We would be there discussing our statistical models and technical aspects of the EM algorithm while Jaime Carbonell, Ed Hovy, and others were talking about semantics, grammars, and linguistic rules. We certainly had no idea what they were talking about, and they seemed to have no idea what we were talking about, either. As I mentioned, nobody in the project could even speak French, so we certainly didn’t have any concept of the delicate intricacies of French grammar that the rule-based based guys were focusing on.
It’s not that we were against the use of linguistics theory, linguistic rules, or linguistic intuition. We just didn’t know any linguistics. We knew how to build statistical models from very large quantities of data, and that was pretty much the only arrow in our quiver. We took an engineering approach and were perfectly happy to do whatever it took to make progress. In fact, soon after we began to translate some sentences with our crude word-based model, we realized the need to introduce some linguistics into those models. Bob and I signed up for a crash course in French. We sat for two weeks listening to lectures and audio tapes in New York City from a guy name named Michel Thomas, who had taught Princess Grace to speak French so that she could assume her royal duties in Monaco without embarrassment. The first novel we read during that course was Candide, so we called our translation system Candide. Soon after completing our course, Bob created a computer-readable morphology of 12,000 French verbs from Bescherelle, and I began studying transformational grammar.
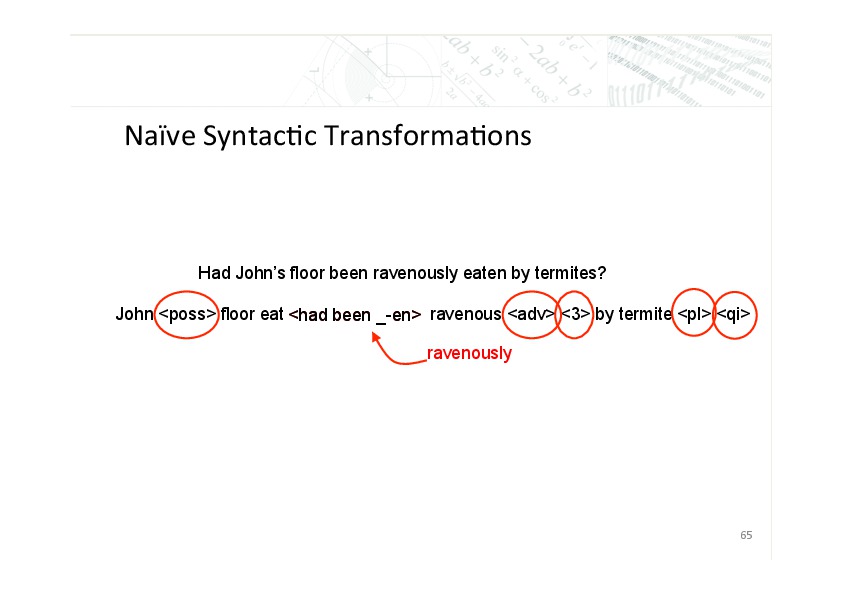
We replaced the words with morphs, and included some naïve syntactic transformation to handle things like questions, modifier position, complex verb tenses and the like. For example, a sentence like, “Had John’s floor been ravenously eaten by termites”, was transformed into this. Where the POS means the preceding noun is possessive, the ADV means that the preceding adjective will appear as an adverb. The 3 means that the preceding item — in this case, ravenously — is to appear in front of the third word of the preceding complex verb, the PL means the preceding word is to appear in the plural form, and the QI stands for question inversion.
Now this is not the type of syntactic or morphological analysis that sets the linguist’s heart aflutter, but it dramatically reduces vocabulary sizes and in turn improves the quality of the EM parameter estimates. Also, by moving to an analysis-transfer-synthesis architecture that used syntactic transformations in both the analysis and the synthesis steps, we reduced the burden on the distortion model during the transfer step. From our point of view, it was not linguistics versus statistics; we saw linguistics and statistics fitting together synergistically.
Now around 1992 we also began including information from bilingual dictionaries. Of course, because we really didn’t know how to do otherwise, we just treated the information as additional data to be thrown into the EM maw. We also purchased some lists of proper names (people’s names, place names, company names and the like) and built those into our system. We were willing to prostitute ourselves in whatever way necessary to improve the performance of our system. As I mentioned earlier, some of us even learned some linguistics [laughter].
Once the basic idea had been sorted out, we shifted our attention to improving the statistical models of the noisy channel and of the source language. In each case, the problem is to construct a model with parameters that can be estimated efficiently and yet characterize the corresponding process adequately. For example, the translation of a particular word clearly depends on other words in the sentence it appears in. But it also can depend on words that appear in previous sentences, sometimes even sentences from the distant past.
Similarly the probability of the next word, morph, or syntactic tag in the source language is influenced by much more than simply the previous two words or morphs. Back then, we didn’t have enough data to estimate parameters for massive conditional models, and I’m sure that even today, with billions of documents available, a brute force 20-gram language model will not work very well. Something more clever had to — and still has to — be done.
Our thought was to employ maximum entropy methods and decision trees. The idea behind the decision tree is to focus on those aspects of the past that are most relevant to reducing our uncertainty about the item being predicted. The idea behind maximum entropy is to demand as little as possible from the data, given the questions the model is conditioning on. We devoted our time in the early 90s to developing decision trees and maximum entropy models of the source language and the noisy channel.

As preparation for this meeting we took Kevin Knight’s suggestion and read Philipp Koehn’s excellent book Statistical Machine Translation. Perhaps the most surprising thing to us was how little emphasis is placed on maximum entropy and decision tree type models. We recently heard that Google uses — well we heard today — Google uses five gram language models and we see in Philipp’s book that rather than focus on development of large conditional translation models, people have moved to the translation of phrases.
We were definitely heading in a different direction 20 years ago. We thought that phrase translations could best be captured through conditional translation models, and we thought that the way forward in language modeling was to divide the past more deftly with decision trees. We, however, are delighted by the current emphasis in his book on discriminative training. In some of our speech recognition work, we’d explored maximum mutual information estimation, but we never got far enough with translation to apply that type of discriminative training technique there. When we read that systems now put weights or exponents on the source and channel model probabilities, we wondered, how can we have been so stupid to have missed that idea? It’s a very natural thing to do, given that both models are missing all kinds of correlation in the data, but to different extents.
So that’s what it was like 20 years ago at IBM. Then, in early 1993, Bob and I each received a letter from some investment company in Long Island proposing that we change careers. We both just threw the letters away because we were very happy at IBM, but on the Ides of March, Bob’s mother was killed in a car accident, and his father followed 20 days later on Easter. When Nick Patterson called Bob a couple of months later to ask why he never responded to the letter, Bob decided to go out to Long Island to investigate. When he returned, he told me that I should also pay a visit. What we found was a small company housed in a high-tech incubator with tiny windows that were high up on the walls because the rooms were originally designed to be chemistry labs. The firm was headed by a mathematician named Jim Simons, who had won some big prize in geometry. Neither Bob or I were geometers, so that didn’t mean much to us, but later we learned that Jim’s original partner was Lenny Baum, yes, the same Lenny Baum who, along with others at IDA, had developed the EM algorithm that made all of our work on speech recognition, typing correction, and machine translation possible.
Then two more things happened. Bob’s third daughter left for college, and my wife gave birth to our first child. I looked at our newborn daughter and thought about Bob struggling with college bills, and began to think that it might actually make some sense to work in the investment area for a few years. After four months of agonizing, I called George Doddington, who was Charles Wayne’s replacement at DARPA, and explained the situation. In particular, that this investment company was offering us 50% more money than we were making at IBM. All George said was “Bye, bye”. The conversation ended, [laughter] and we left IBM and the natural language field.
Upon arrival at Renaissance, we quickly learned that the financial world is different from IBM Research. It’s ruthless. Either your models work better than the other guy’s, and you make money, or they don’t, and you go broke. That kind of pressure really focuses one’s attention. When Bob and I, and then Stephen and Vincent Della Pietra, left IBM, we just never had time to look back. Because everything is hush-hush, we lost all contact with the outside world. We went into a cocoon and focused all our energy on just staying afloat.
Bob and I both lived at our offices for the first year, and in fact, after 20 years, I’m still sleeping there three nights a week. With the exception of one minor recruiting trip, this is the first business trip either of us has taken since we spoke at the translation conference in Montreal in 1992. This past summer, my daughter was interning at the National Economic Council in Washington. One evening, I asked her what she did for them, and she told me that she’d been translating some documents from Chinese into English. I said “Wow, that must be time consuming!” She said, “Oh, not really, I just use Google translate and then clean up the results” [laughter]. “What?” I asked, “Machine translation is really that good?” “Oh yeah, dad, didn’t you know that computers can translate from one language to another?” [laughter] [applause] I went online and was actually shocked at how much progress you guys had made during the past 20 years. The field has certainly moved from an IBM luxury to something very real and very valuable.
A while back I read a paper by Robert Gordon, titled Is US Economic Growth Over: Faltering Innovation Confronts the Six Headwinds [PDF]. In that paper, Gordon argues that historically there were three great waves that innovation that propelled economic growth. You know, things like steam engines, running water, electricity; but that there will be no more. As we stand here in awe at all you’ve accomplished in the past 20 years, we realize that Gordon and the doom-and-gloom, innovation-is-dead guys are just plain wrong. It’s clear from all you’ve done that the progress that scientists will make working in natural language understanding is going to go on for a very long time.
We both really envy you all the fun you must have had, and all that you must still be looking forward to.
Thank you very much. [applause]
Philip Resnik
Wow, I’m very honored to have been asked to moderate some discussion after this morning, and that’s extremely cool. I want to just set a little context for me; actually, I want to set a little context for these guys, also, in a way. Some of you may or may not know the story of Rip Van Winkle. It’s written by the same author who wrote the Legend of Sleepy Hollow, The Headless Horseman, that people may have heard more of that.
Rip Van Winkle was a guy in the Catskill Mountains in New York, not that far from T. J. Watson. He was rather henpecked at home, and he liked to drink. One day, in order to try and get away, he went up into the mountains, and through magical circumstances fell asleep for 20 years. He woke up and his beard was a foot long and his gun was all rusty and he came back to his town and he really had no idea what was going on. He got himself into trouble immediately by proclaiming his loyalty for King George III because, actually, he’d fallen asleep before the Revolutionary War, and then woken up after it.
After some initial misunderstandings, he wound up being welcomed into the community and kind of reuniting with everybody, reacclimatizing himself to everything that was going on. Wikipedia tells me that this story was viewed by Dutch readers as a wonderful comforting tale of how you can actually sleep your way through a war and have a happy ending at the end.
It just seems like it’s a little bit of an analogy here. I was lucky enough to intern with these guys in the summer of 1991, working on the decision tree language model stuff, and lucky enough to meet John Cocke. There were just these enormous changes that were taking place. One thing that was weird for me, was that I was the linguist. These guys were like, “Oh yes, you’re the linguist in the group”. Then I got back to U Penn, and a bunch of us there were the antichrist to the rest of the linguistics community, because we were doing this statistical stuff.
One last reminiscent thing in that category also. For those of you who knew Fred Jelinek — and this may come as somewhat as surprise, actually — I found Fred to be so much less scary than these guys when I was there [laughter].
One or two introductory sort of things to set the context for broader discussion. One is an observation. Bob pointed out in talking about the 1620 going to the 6600: The idea that big changes in scale can lead to big qualitative changes in the way we do things and our thinking. Peter echoed that when he talked about “the force of crude computers”; once you get the computers to be less crude, you can do stuff on a scale. Really, it’s not just about scalability, it’s at some point scalability changes the way you think about things. That’s a really positive side of what’s happened with this kind of revolution that started twenty something years ago.
At the same time there’s a little bit of a flip side. I don’t know how many of you work in IT have had this experience, but it’s really awfully depressing to spend a year working on an interesting research idea and then discover you can get a bigger BLEU score increase by, say, doubling the size of your language model training data. I see a couple of nodding heads. There’s really two sides to this coin of scalability, and I think that’s one potentially interesting thing to discuss.
I think that it would be great to have these guys come here and people ask questions about the history and the rest. I also think it would be great for people to talk about some of the bigger issues in where we are, in the context of the stuff that they’ve talked about today. I kind of want to encourage both, and also to get their thoughts on it, because Rip Van Winkle coming back had insight and wisdom to impart, even though he’d been asleep for twenty years.
I just want to mention three things, to throw them out on the table and see if anybody wants to talk about them, and if not, that’s also fine. One has to do with this return of semantics. It’s wild to be at a natural language processing conference and have people frequently talking about language understanding. Because understanding was kind of a dirty word for a long time (although semantics was a dirty word for a long time). I think that’s a really an interesting issue that’s worth discussing.
I also want to hasten to add that if you haven’t already, you need to read a paper written a couple of decades ago called Artificial Intelligence Meets Natural Stupidity [PDF], which is all about not thinking that just because your model includes symbols that have meaning to you, that it actually understands. Just because we’ve put EAT in all capital letters in our model, doesn’t mean that it naturally knows something about eating.
The second issue I want to throw out on the table is this question of what are the right units. We’ve been talking about words and phrases and hierarchal phrases; we’ve had a proposal we go all the way to the dots and dashes of Morse Code. Other people in this room have introduced the idea of document-level consistency, taking the one-sense-per-discourse idea that came out of sense disambiguition, and applying that in a machine translation setting. What are the right units here if we’re going to get the problem right, because translating sentence-by-sentence, and using the size units that we’ve gotten, may or may not be right.
A third thing that I want to throw on the table here echoes some of the stuff that Philipp Koehn was talking about. I’ll assert it, and people can dispute it everything: Machine translation is actually not the problem we’re trying to solve. Fully automatic machine translation is the wrong problem. The problem is getting translations that are available when you need them, cost-effectively, that are good enough for whatever the job is. Having a computer produce translations is one way of going about that. It’s only one way of going about it; it seems like the obvious way of going about it. But as Philipp points out, there are actual human beings in the world who have capabilities that computers don’t. There are things that computers can do that people can’t. I want to put on the table the idea — maybe because I can get away it, there’s nobody from DARPA in the room — that actually the machine translation formulation of the problem that we’ve talking about this whole morning, is actually the wrong problem to be trying to solve. That’s not what’s needed. Machine translation is one of many possible means to an end.
I just want to throw some things out on the table, to get people thinking, maybe prime the pump a little bit. I’d like to invite, if you’re comfortable with it, for these guys to come up and join us up here. And Vincent, Stephen: If you’re comfortable I know that we would love to have you up here; if you’re not comfortable with it, feel free to pipe up from over there.
Male
Watch the mic at your foot.
Philip Resnik
Thank you. As I said, I think there’s a broader discussion to have; I also think that probably people have questions about the history of stuff. Theoretically, I’m moderating this thing; having primed the pump, I’m going to now turn it open and start the panel.
[inaudible]
Philip Resnik
Yes, although it’s a small room, so if you stand up and speak really loudly I think it’s probably [crosstalk]. If the mic becomes a hindrance to discussion, then I’ll encourage people to stand up and talk loudly.
Dan Jurafsky
I just have a very quick historical question. I love this image of Fred Jelinek at the beach and you guys sneakily working on machine translation, but you didn’t say why machine translation. Why’d you switch, what made the switch from speech to MT a thought?
Bob Mercer
Probably because of the Hansards data.
Philip Resnik
Can people at the back hear him? So so.
Bob Mercer
I personally feel that the Hansards data is a group of data that is a great place in which to investigate meaning, where “meaning” means, or at least I personally think, the French that’s written there is the meaning of the English that’s written in the other place. You don’t need to worry about all that intermediate stuff of this what it really means. I think it would be quite interesting to get somebody to take 100 million words of English that are commands for doing this or that and translate it into some formal language of commands, so you could then apply this type of thing to figuring out what’s the meaning of English from that point of view.
That’s what I liked about the Canadian Hansards data; I think that’s what appealed to John about it as well.
Male
John brought the data and then you guys just say hey, we could translate.
Bob Mercer
John pointed out that the data [crosstalk] existed.
Philip Resnik
I’m going to encourage people to feel free not to use the mic if you can speak loudly, because I think that’ll create more of a discussion kind of atmosphere rather than a stand at the mic and throw questions atmosphere.
Kevin Knight
Another technical question, a technical question.
Peter Brown
I’m not going to remember anything technical [laughter].
Kevin Knight
I think I [inaudible] mentioned this, so in your 93 paper you give you training set perplexity, which more or less shows that your EM was implemented correctly, and show that perplexity improves iteration by iteration. But you didn’t give test set perplexity. On the other hand, with language modeling you have very frequently given test set perplexity, and we probably wouldn’t even think about giving training set perplexity. Was there a reason not to do test set perplexity in the translation world?
Peter Brown
No, I think there is every reason to do it…
Bob Mercer
No excuse [laughter].
Robert Frederking
In the spirit of reminiscence, the funniest talk I’ve ever seen was one Peter Brown gave [inaudible] and he had Fred Jelinek in the audience heckling him about how can you this without linguistics. He kept saying over and over again, well Peter, surely you must have to have linguistics to do that. Everyone knew the inside joke was that story about Fred, supposedly having said that every time he fired a linguist, his error rate went down, so it was very amusing [crosstalk].
Bob Mercer
He actually did say that. That’s not a story that he said it, he did say it. And it was true! [laughter]
Philip Resnik
[inaudible] Some of my best friends are linguists.
Peter Brown
No but he kept bringing in linguists.
Bob Mercer
Fred always hoped that he would find the linguistic philosopher’s stone that would turn all these things in to gold. Unfortunately it hasn’t come along yet.
Noah Smith
One of the things that I remember — I worked with Fred a little bit at Johns Hopkins after he’d left IBM. One of the things I remember him talking about, he would always make this joke that English and French were basically the same language, disparaging the idea that we should just be working on English and French because of the utility of the Hansards and the ease with which we could get a lot data for that language pair. I always wondered whether, he always said it like it was the dirty little secret of statistical MT, that English and French were the easy ones to be working on. Now as you know we work on lots of languages. I’m curious whether at the time you felt that way, or the data led you to think that. Or you had plans to look at other languages or …
Peter Brown
I think that we were really lucky in that English and French are basically the same language, and secondly it was the data. If it was data in Japanese, we would have worked on Japanese, and it would have been a lot less successful. It wasn’t very successful until you guys fixed it up. Yes, we were just lucky that this data existed.
Philip Resnik
There’s an analogy too there, if Chomsky had started out working with free word order languages — of which there are plenty in the world — then classic syntactic theory would probably look a lot different from how it does today.
Matt Post
I’m curious, as to whether you have filled your daughter in on your early work and whether she is impressed?
Peter Brown
You must not have kids, they don’t really care about what their parents have done. [crosstalk] [laughter]. Yeah, they don’t care.
Victoria Fossum
I found it was interesting how you mentioned when you read Philipp’s book and found out what was happening in the last decade, you mentioned one or two things where you thought, oh wow, I can’t believe we didn’t think of that, it seems really obvious that we should have done that. Was there something that occurred to you when you were reading what’s been going on, where you thought, I can’t believe we haven’t done this thing yet, that seems really obvious to us now?
Peter Brown
I thought that the whole field was moving in the direction of maximum entropy and decision trees. I don’t know what’s happened since we left the field, the only thing we know is what’s in that book [crosstalk] [laughter]
Male
It’s a pretty good approximation.
Peter Brown
It’s really an excellent book, I was really impressed by the book, but there wasn’t a lot about maximum entropy and decision trees in that book, so we feel that the field just went in a different direction than where we were heading. [unintelligible]
Bob Mercer
We published a paper some time ago. [unintelligible]
Peter Brown
Class-based language models?
Bob Mercer
No the 20-grams [inaudible].
Peter Brown
[inaudible]
Bob Mercer
Anyway, we were trying to build a decision tree language model with a 20-gram history. This effort took about a year of CPU time back then, which you could probably do in an afternoon these days. Anyway, back then it was a long time thing. It had a 5,000 word vocabulary and produced quite a significant improvement over just trigrams without really being any bigger. Trigrams, which have a 2-gram history that’s actually occurred, there aren’t really so very many of them. With just the same number of states, this produced a better language model. That’s the type of thing that we would have expected would be done by people, with so much data and so much computation.
Bob Moore
Actually I’ll comment on, I have a particular take on this which is for the last 20 years the main thing we’ve been doing as a field is catching up with the amount of data that has become available to us in electronic form. It has been most economical for us to do very naïve things for a very long time. I think though what we’re seeing is certainly on high resources languages that growth curve has leveled off. It looked exponential but turned out to be a sigmoid. We can actually anticipate where we’re going to be, even in the long tail language pairs, by looking at the state of the world today. We will never have as much language in Swahillian-English say as we have in French and English today. If we had put all of the Swahilli that’s ever been produced in translation into electronic form, we still wouldn’t have as much because we don’t how to handle it. Swahilli’s never a global international language. I think, now we’re at this point where we can change or we sort of know, to a rough extent, what the magnitude of the data that we’re working is, and we know we have to deal with modeling. It’s been so easy for us to just say, well, let’s just build a slightly faster [inaudible] while we’re waiting for the machine to get bigger to deal with more data. That’s kept us from doing these more interesting model approaches.
Peter Brown
My sense is — again, from reading Philipp’s book, which is all I do know — is that going to phrases, that wasn’t just a question of more data that was just … see, we would have handled that by asking questions. In fact Bob has always wanted to do letters and not words, he views words as selling out [laughter]. By asking questions and through a decision tree or a maximum entropy type format, rather than just treating the whole phrases at once. But that’s just a different approach, I don’t think there’s…
Chris Dyer
It is, it is, and that was modeled in our innovation, certainly that happened to give such immediate benefit. I think it pushed us though in a different direction. There is a group of us in the field that are interested in asking questions and one of the interesting things in that work is learning what questions to ask automatically.
Philip Resnik
Let me, I’m actually curious about, the desire to do things in that way right, is that driven by …
Peter Brown
Linguistic intuition [laughter].
Philip Resnik
That’s actually where I’m going with the question, right, because we have a good handle on ways of doing things, right? So the conditional model of asking questions, that sort of thing, versus thinking if that was actually the right units for translation. Are they the right units in your mind and that’s why you want to go in that direction?
Peter Brown
[inaudible] If you want to do agreement, I don’t think the right way of doing it is to look back at 5-grams, you just need so many of them. Better to look back and ask questions about, where’s the noun?
Male
Right.
Peter Brown
We just thought that’s the way everything was going to go but it didn’t and that’s a surprise to us.
Bob Moore
I wanted to take a stab at answering, trying to explain why the field hasn’t gone into the particular direction of decision trees and maxent. I think a central reason was that due to a paper Franz wrote about 2002, I think, or maybe 2003. I can’t remember which. And the convergence on this BLEU score metric that some of the people at IBM after you guys left came up with, as the standard evaluation metric in MT. The fact that it’s a non-convex objective and it doesn’t correlate particularly well with probability. Actually that was one of the things Franz showed. I guess your 2002 paper [PDF] was on maxent, and your 2003 paper [PDF] was on MERT. So Franz had this pair of papers where he did do maxent for optimizing his overall translation model, and then he showed in a paper the following year that if you had a metric like BLEU or if you had several others that if you directly optimized for that metric that you got better results on that metric than if you optimize for probability.
So that was what shifted the field going from maxent and optimizing for probability to optimizing some other objective directly. At the same time, he proposed this minimum error rate training [PDF] algorithm for doing that. That algorithm had the property that it didn’t scale beyond a few tens of weights to optimize. It wasn’t until three or four years ago when these two guys published a paper called … I’m sorry … You’re not David Chiang now, David was sitting there earlier. Over here. Published a paper, what is it called, “11,001 New Features”, or something like that, that people really started really exploring other optimization methods that could still be used to optimize the BLEU metric but with a much larger number of parameters optimized. There has been a lot of work in that, but again, it’s not maxent because we find when optimizing the desired objective directly seems to work better than optimizing for probability.
Peter Brown
The funding goes to the BLEU metric, is that how that works?
Bob Moore
I’ve been out of the DARPA world for fifteen years, so I don’t worry about that.
Philip Resnik
It’s certainly highly correlated.
Male
Highly correlated with perplexity problems.
Philip Resnik
Yes, actually that’s taking place in other areas of NLP, too. In parsing and also in topic modeling …
Bob Moore
If I could add one more footnote to this. Why not decision trees, and I think the reason there is when you’re doing these direct optimization methods for discriminative training, you can throw all kinds of features in without the tree constraints on the definition of the features. So I think people are finding that they can address the kinds of things that you’re interested in without the tree constraint that comes from decision trees, and without optimizing for probability that you optimized on. But it wasn’t …
Peter Brown
What’s the state of the art? Is it straight 5-grams, not class-based 5-grams or anything like that?
Franz Och
The Google system has straight … it used to be 4-grams, until some time ago, and now we switched to 5-grams.
Peter Brown
That’s really the crude force of computers.
Philipp Koehn
We do use 5-grams [inaudible];
Philip Resnik
It’s worth noting, too, a lot of the action in broader context is not in the language model context, it’s in the translation model. That’s where a lot of the contextual stuff — so going from phrase-based models to hierarchical phrase-based models, which is basically synchronous context-free grammars, let’s you actually capture relationships.
Bob Moore
But I would emphasize that the field was stuck on MERT and limited to some tens of parameters to optimize right about the time when Philipp was writing his book, so I don’t think this book really reflects the growth in high-dimensional feature models.
Philipp Koehn
That was the chapter I was really struggling with.
Bob Moore
Right. It was just kind of exploding at the time he was finishing his book.
Philip Resnik
Now, totally in explosion phase …
Dekai Wu
So I’m going to save my technical comments for later, but while we have these guys here I’m, like Dan, interested in the history. I’ll tell you where this is coming from. So back in 1992, when I decided I’m going to replicate the IBM models on Chinese-English and arrived first here in Hong Kong and HKUST and said, our government also is legally required to keep bilingual proceedings. Let’s go get the Hong Kong Hansards. I went into the office and — this might be interesting to the people who were in high school back then — and talked to them. They said, “Yes, we have to keep” … they have several dozen permanent translators working on translating everything from English into Chinese and vice versa whatever was said in the Parliament. They said, “Yes, we do this.” I said, “Oh great, can I have the data?” They said, “Yes. Well.”. “Okay, what form is the data in?”
“Well, the data is in, so this is Hong Kong. It’s Cantonese, it’s not really Mandarin. We sort of try to convert it into Mandarin but there’s a lot of things that are said, they use Cantonese words that don’t actually have official characters.”
“So what do you do?”
Bear in mind, this is pre-unicode. Hong Kong is traditional Chinese and [inaudible] and so they’re using the kind of Taiwan encoding called Big5. But that doesn’t contain code points for the Cantonese characters. So I said, “What are you doing?”
“Well, we’re kind of making it up as we go. We’re making up codes here in this office.”
“Where’s the standard?”
“There is no standard.”
“How are you creating this?”
“We’re making up our own fonts for these characters using this software.”
“What word processing software are you using?”
“We’re using Macintosh.” They were the only people in Hong Kong who were using Macintoshes back then. They said, “We’re using this word processing software, it’s made by blah, blah, blah.”
“That’s the company that has gone out of business four years ago. You can’t get that software anymore.”
They said, “Yes, that’s true but we’re still running along on it.”
“Where do you store these files?”
“We store them in all these little 8 mm magtapes in an Apple proprietary cartridge form that Apple canceled five years ago.”
“Where’s the data?”
“It’s sitting up on those shelves in these stacks of …” [laughter]
“How do you read that?”
“We have one reader.”
So I have to spend the next five months tracking down a reader somewhere, figuring out their — tracking down the obsolete word processing software which we couldn’t get anymore, and figuring out their code points. And then, doing all sorts of acrobatics to clean up the data and eventually give it back to them, and now it’s become part of the LDC Hong Kong Hansards. At which point we could start replicating the IBM models. Did you have to go through any of this with the French Hansards, the English-French Hansards?
Bob Mercer
No, it was pretty clean. [laughter]
Matt Post
So I was interested in Philipp’s comment about your paper being written in math and actually being about natural language processing. I think that’s a common reaction, but another part of that is your paper is held up as being very delightful to read. The prose is very technical but it’s also … there’s a lot of … just the manner it’s written is very interesting. I wonder if you could comment at all on how the writing of, particularly the 1993 Computational Linguistics article, came together.
Peter Brown
So Bob and I have worked together, I don’t know, thirty years now, and we write a lot of stuff. Even at Renaissance, since we’ve been in management now for a long time, we end up probably writing more legal documents than computer programs. Anyway, we write a lot of stuff together and we’ve always used exactly the same technique, which is, I write the rough draft —
Bob Mercer
In about five minutes.
Peter Brown
— because I write very fast, but not so well. Bob then cleans it up. He writes very slow and extremely well. On the other hand, I want to mention something about this ‘93 paper, he gave it to his brother to read who said, yeah, it’s an interesting paper but my god, it’s terribly written! Anyway, everything we write is written in that way, including this talk.
[unintelligible]
Noah Smith
So coming back to this, why didn’t we go the maxent and decision tree route? I think one thing worth pointing out, as one of the few people in the room who’s not primarily a translation person, is that those ideas had maybe a bigger impact more immediately in other areas of NLP. So you probably wouldn’t have seen it in Philipp’s book, because it’s a book about translation. But if you read current papers in other areas like parsing, semantic analysis, tagging and chunking and morphology, there maxent models maybe in newer form. So for example, John Lafferty in 2001 published a straight paper on something called conditional random fields, which are basically maxent models over whole structures. That has been an incredibly influential idea and it’s still the gold standard for how we build these kinds of models when we have labeled data for parsing and tagging and those kinds of things.
We may have changed the objectives a little bit; we changed the optimization algorithms that we used. One thing that is still … your seminal work with John on inducing features in random fields, when we talk to people about how to do feature induction, we still point to that paper as one of the key readings. There’s just been not a whole lot of development on that front in at least for discrete modeling in language. There are few exceptions to that but that line of work was incredibly influential beyond machine translation. I think now, MT had been a step behind the rest of NLP in embracing it. Decision trees, I don’t know, we should look at that again.
[inaudible]
Lane Schwartz
Yes, so I’ve got another historical question. In the paper, you talked about the models building on each other and using the earlier models to help build up the later models. I was wondering if you could talk a little bit about that development: The sequence, Was the Model 5 the first one? Did you start with that idea and realize, I need these earlier building blocks? And also, what did you actually have decoders for? Was Model 1 strictly a building block? Did you ever want to try to build a Model 1 decoder? How did that process work?
Peter Brown
Well, I have to try to remember what these different models are. [laughter]. I remember just a few tidbits, which may not answer your question. I do remember being quite pleased when we learned that Model 3 was convex, and therefore we could train, it to get to the global maximum.
Philip Resnik
Model 1.
Peter Brown
Model 1 …
Bob Moore
And Model 2.
Peter Brown
Model 2, one of those (laughter) … Is it only Model 1 that’s convex?
Chris Dyer
It’s just Model 1 that’s convex.
Peter: Anyway, we were pleased by it. [laughter]
Stephen Della Pietra
We never decoded anything, I think less than Model 3.
Peter Brown
What do you mean?
Stephen Della Pietra
Decoded. [inaudible]
Peter Brown
We’ll get to that later, anyway. [laughter] But the problem was the other models you just couldn’t do the computation without pruning, and in order to prune, you needed to get decent estimates to begin with. So with a convex model, we knew we could optimize things globally. Then Model 4 just offended us because it placed probability on things that couldn’t occur. What was the word we used? Deficient, yes. [laughter] [crosstalk] We knew that model was wrong so we had to build Model 5.
[unintelligible]
Chris Dyer
So one interesting historical development, about that time, there was all this work on Monte Carlo methods were becoming very popular in statistical inference and things like that. You guys also came up with your own solutions to inference problems that are today, historical curiosities a little bit. Were you guys aware of what was going on in statistics, and was there a reason you thought this Gibbs sampling stuff is not a good idea?
[unintelligible]
Bob Moore
Yes, I just wanted to make another comment about the history of maxent in the field. Actually after you guys published the maxent paper in Computational Linguistics so there was a lot of interest in it, but the field didn’t actually start getting really good results using maxent until the late 90s, early 2000s, when they figured out you need a regularization penalty to avoid over fitting. I remember going to a lot of statistical speech and natural language meetings in the late 90s when people were saying, we tried maxent language models but they really weren’t any better than simple N-grams.
Philip Resnik
Why don’t you give a two-word summary of that regulation development.
Bob Moore
Okay. Yes. It’s just putting a penalty on the optimization criterion that you penalize typically by the sum of the squares of feature weights. So it prevents learning too well how to maximize the probability of the training data at the expense of bizarre feature weight combinations.
Peter Brown
We know about that stuff.
Bob Moore
Okay. Anyway, it wasn’t until people started really focusing on that and figuring out how to adapt the optimization algorithms to include a regularization penalty that people really started getting good results with maxent techniques.
Male
As you moved from doing machine translation to trading, what were the skill sets that you had to acquire, and also could you use anything that you learned in your ten years or twenty years in doing speech and machine translation that is relevant to what you’re doing today?
Peter Brown
You want to know about finance and that kind of stuff? Yes, so when we arrived at Renaissance, Renaissance was started by a couple of mathematicians. They had no idea how to program. They’re people who learned how to program by reading computer manuals, and that’s not a particularly good way of learning, unless you’re Bob reading Algol manuals. So they didn’t know how to build large systems where you could make sure that this system produced the same answers that the mathematics did. From building speech recognition systems and translation systems, we learned how to build pretty big systems where you can have a lot of people working simultaneously on them, so we definitely used that skill set. Then it’s just a question of estimating parameters from a lot of data. If you look at our blackboards, they look exactly like your blackboards. Full of similar kinds of equations. The big difference in finance is that the level of noise is much greater. It’s all noise in finance and there’s more structure in natural language models.
Male
[inaudible]
Bob Moore
There’s no arguing about the evaluation parts …
Peter Brown
I have to say, that is the sort of a nice thing because these squabbles you get into … As Bob said, it’s nice if you’re making money. The problems you get into, I don’t know if that still happens with you guys, but there were squabbles over whose papers are more important, or who discovered what first or that kind of stuff. There’s none of that in our field because nobody writes any papers in finance. [laughter] But otherwise it’s exactly the same. You’re just sitting there building models with data and writing programs to optimize functions based on the models and that’s that. So the skills are exactly the same except there’s more statistics because you have to worry about noise a lot more.
Lane Schwartz
So Peter, you mentioned that Bob thought that words were selling out? I was just wondering what were your thoughts on using letters, because there have been at least one paper that I could think of where somebody did try to build a statistical translation model over letters. What were your thoughts along that direction?
Peter Brown
You’re asking me?
Lane Schwartz
You.
Bob Mercer
You know the reason I like letters is that there are very few words in English, and I suppose it’s true in others as well, where you say one, this, and two, something entirely different. Cows for example, you can have one cow, you can have two kine. But there aren’t many examples like that in English. And I don’t think it’s an accident that we don’t call this a church and two of them a schlemiel or something like that. There’s a simple connection to get you from the singular to the plural, and there are simple connections to get you from the simple form of a verb or an adjective or, whatever, to all the various florescences that these things have when people speak. So I always felt that we should be modeling letters, because there are only 26 of them, or 24 or them, or 30 of them, or however many there are, depending on what alphabet you’re writing with. It’s such a smaller number than 500,000, however many words there are in English. So it just seems to be clear that that’s the way one ought to be doing things. To the extent that we can’t succeed at it, it’s because we haven’t had the right ideas about how to do it yet.
Philip Resnik
So one of the things that linguists do is think about the levels of, you know, multiple levels of abstraction. The models, if you were doing that, probably would involve inducing some subset of abstractions like the notion of word groups …
Bob Mercer
I doubt it.
Philip Resnik
No? Maybe?
Philip Resnik
I’m curious. At that time, Ezra Black was there when I was there. Were there linguists around?
Bob Mercer
Yes, there were.
Peter Brown
Fred kept bringing them in.
Philip Resnik
I know, yes. [laughter] I was just curious if you wanted to say a word or two about life with linguists? Or whether that was completely irrelevant to your thinking at the time.
Bob Mercer
No, I wouldn’t say completely irrelevant. I think that linguists are interested in different things from people who are trying to recognize speech or translate the sentences or what-have-you. Well, here’s what I think is the difference between linguists and physicists. Physicists are people who find two completely unrelated things and point out to you how they’re really a manifestation of the same thing. Linguists are people who find some things that most anyone would think are just exactly the same and show you how tremendously different they are. [laughter] So I think that they’re just into a different kind of thought entirely from physicists. We’re more like physicists than linguists.
Philip Resnik
Anybody want to comment?
Bob Mercer
I hope there aren’t any linguists here that I’ve offended.
Bob Moore
I find it interesting that Bob confirmed the famous quote abour firing the linguists which Fred spent a lot of the last years of his life denying that he’d ever said.
Bob Mercer
Not surprising to hear.
Male
I have a question about your comparison with your former life and your current life? [unintelligible] What is the balance between those more complexity and just vasts amounts of data in your finance world?
Peter Brown
We have to be careful what we can say here. I think we can say this. When there’s more noise then the model is not as complex.
Male
English and French, they’re more like the same. But in finance, things change all the time.
Bob Mercer
The real problem in finance is that you’ve got competitors and if there’s some piece of not-noise that sticks its head out, someone may see it. If you find out that if I check the price of Apple at 3:15 PM then I should buy something-or-other three weeks from now, people will find that out, and it won’t take long, and it’s very profitable if you find a little thing like that. So there aren’t many of them. They keep getting knocked down by people who discover them.
Peter Brown
So for example we can talk about the journal club where … some … yes. Jim, there are certain similarities with Jim and Fred. So Jim Simons, who founded our company, kept thinking we should look for more ideas elsewhere, and so we started a journal club. Each week we would read three papers in the financial literature; they would be assigned, and people would present them and review them to see if there were any ideas. We read hundreds of papers and I don’t think we found a single idea in the papers that actually worked. This is because for a number of reasons. One, the people who write these papers, their goal is to get their PhDs or to get tenure or to become famous or something. They’re not so much concerned about making money.
So they tend to overfit the training data. But the other thing is, once something is published, and the world sees that there actually is something there, then it’s traded out very quickly. So this thing about competitors is a real issue, which is why we’re not giving a talk about finance. It’s why this is the first conference we’ve been to in 20 years, because people just can’t talk about ideas, because as soon as they’re out, they get traded out. It’s also why the data is so noisy. So any time you hear financial experts talking about how the market went up, because of such and such — remember it’s all nonsense.
Philip Resnik
It’s worth noting by the way. I think that this non-stationarity of the data is something that in MT we ought to be paying more attention to. We are in fact behaving as if language is more static than this. Of course, you mentioned earlier that the discussion of high resource and low resources languages. There’s a lot of stuff, this idea of adaptation is something that is becoming increasingly important as we start to hit walls, and move not just from high resource to low resource, but from newswire and political text or the proceedings of stuff that comes out regularly, to languages for which we just don’t have as much data. We have to find ways of getting leverage from what we do have, the models we’ve already built.
Peter Brown
Let me raise one of the differences with finance. In natural language, you can always get more data, by typing in Lassie novels or whatever kind of thing like that. In financial data, there just is what there is and that’s it. You can’t create more data on price movements, and so that’s frustrating. You can’t take the Google approach.
Philip Resnik
Well, if you use text, then you can just piggyback [inaudible].
Peter Brown
If there’s signal in it.
Chris Dyer
Yes, we’ve all heard that Twitter is the secret to successful hedge funds these days.
Peter Brown
So I read the Twitter paper. There is a paper on Twitter and the predicting market movements by, some woman in the Midwest, Iowa or something.
Chris Dyer
Indiana.
Peter Brown
Indiana. I knew it was one of those I states. I think if you look, she predicted movement of the SMP index for 14 days in December…
Chris Dyer
I think it was 17.
Peter Brown
Seventeen. I mean, really! I can’t comment on what’s in Twitter.
Male
[inaudible].
Peter Brown
But I have heard that Google has decided not to go into the business, is that, can you confirm that?
Franz Och
So it’s basically, you use something like Google Trends …
Peter Brown
For trading, yes.
Franz Och
Yes, I heard something.
Peter Brown
That’s what they’re claiming …
Franz Och
That’s certainly a possibility. But Translate is open for everybody. [unintelligible]
Philip Resnik
Also on history, or on larger issues?
Matt Post
Yes, what about the phrase, spraying probability mass all over the place? Do you remember that one from the 93 paper?
Peter Brown
I remember …
Matt Post
As a justification for the Bayes’ rule approach? That’s just been …
Bob Mercer
Model 4.
Peter Brown
That’s the deficiency issue.
Matt Post
I think it was part of the justification for using Bayes’ rule to break it down into …
Bob Mercer
[unintelligible]
Peter Brown
Oh, this is why we go forward instead of backwards.
Matt Post
Right.
Male
And backwards instead of forwards, right?
Philip Resnik
Any other thoughts?
Bob Moore
I’m going to try to get them to say a little bit more about what it is you actually do.
Peter Brown
Now, or?
Bob Moore
Now. Earlier, you said, you find some little thing you can exploit and then eventually everyone finds out about it, and it’s not worth anything for you anymore …
Peter Brown
That’s why we keep it quiet.
Bob Moore
Is there something, some concrete example that you could give us?
Peter Brown
Sure …
Male
20 years ago that everybody knows …
Peter Brown
I have an answer to this question. In 2003, we used to have investors. Then we threw all the investors out at one point. But in 2003, they’re at our last investors’ meeting. Jim said, you’ve got to give them one example. So we did disclose one example but as you could imagine, that example is not a particularly valuable example, but it is something that can give people a good sense of what we do. One of the datasets we purchased is cloud cover data. It turns out that when it’s cloudy in Paris, the French market is less likely to go up than when it’s sunny in Paris. That’s true in Milan, it’s true in Tokyo, it’s true in Sao Paulo, it’s true in New York. It’s just true.
Now, you can’t make a lot of money from that data because it’s only slightly more likely to go up. But it is statistically significant. The point is that, if there were signals that made a lot of sense that were very strong, they would have long ago been traded out. So either there are signals that you just can’t understand, but they’re there, and they can be relatively strong. There’s not many of those. Or, much more likely, it’s a very weak signal, such as this cloud cover data signal. What we do is look for lots and lots, and we have, I don’t know, like 90 PhDs in math and physics, who just sit there looking for these signals all day long. We have 10,000 processors in there that are constantly grinding away looking for signals.
The idea is that any one of these or any handful of these wouldn’t be enough to overcome transaction costs, but if you combined lots and lots and lots of them together, then you can overcome transaction costs and you have something. So it’s a lot of weak signals like this cloud cover data, but that’s the only one I’m going to disclose no matter how hard you push me.
Bob Moore
That’s very useful, very helpful.
[unintelligible]
Peter Brown
Yes, I would say … all the same, except you guys probably have more fun.
Dan Jurafsky
So, the way we find out about these weak signals in our field from each other is we write papers. And so presumably you don’t, so how is it, is there a perfect intellectual market for you where somebody figures out something, right, or how do you know when people are figuring out the things?
Bob Mercer
We have 90 PhDs that meet as a group once a week.
Dan Jurafsky
No, I meant …
Male
How does the intellectual community …
Philip Resnik
How does the field of finance … ?
Peter Brown
So how do we know whether other people are finding out these signals also?
Male
Yeah.
Peter Brown
We don’t know which exactly signal they’re finding, but what we can see is that a system from 10 years ago or something like that, gradually degrades with time, and that must be because other people are catching on. So we just have to keep extending the building and hiring more people and it’s annoying but that’s the way it is.
Philip Resnik
Similar to a different thing I’m curious about, as we point out a lot of similarities, one of the things methodologically that a lot of people in this room are doing — Franz, you’re kind of like a master of it — is error driven improvement of systems. It’s not just you’re pushing things forward through the models but you’re then actually looking at what it did and using that to inform and go backwards. Is that a part — to the extent that you can say, and it’s hopefully high-level enough that it’s an okay question to ask. Methodologically, is it simply a question of doing a lot of crunching and seeing and doing evidence combination and seeing what works, or is there are a certain amount of the kind of old-fashioned error analysis, driven by the data, but with a human that’s looking there and saying, this led us down the garden path. To what extent is that part of your process?
Bob Mercer
I don’t actually know the answer to that question, but I’ll tell you this. There are, Peter mentioned the importance of doing things right. [unintelligible]
Male
Use the mic.
Bob Mercer
Sorry. I got the mic here. The people at Renaissance, when we arrived, didn’t really know how to make big systems. [inaudible] People who come to Renaissance think that they’re going to find sources, and I think Peter and I thought we were going to be predicting the price of Apple tomorrow and that kind of thing. We have people who do that kind of thing. Some people are much better at it than others. [unintelligible] I don’t look for sources myself. But people that do, you could call them prospectors. They’re the kind of people who look and say, I think there must be gold over there, and sure enough, there’s gold there. Some other person digs a hole and says, dig another hole. He has no idea what he’s doing, but still, there’s plenty of stuff that he’s doing that isn’t doing that. I don’t think either of us can really comment on how people find sources. It’s a knack that some people have.
David Yarowsky
Yes. It sounds like you’re at war. No less stressful an environment than Turing was trying to break Enigma. If finance, sorry, if profit was not an issue, if you had the same income from what you do now and what you did before … which is more intellectually interesting, which do you like more …
Peter Brown
What you guys do is much more interesting.
Bob Mercer
Definitely at least, I would definitely do this rather than that. It is a war. But it’s more peaceful than the war that Turing was in.
Peter Brown
My dream is when it all ends, to go back to what you guys are doing. What you guys are doing is much more fun. Bob has big spending habits, so… [laughter]
Lane Schwartz
So there’s a quote, in one of your guys’ papers, I think it’s about the statistical NLP people are one of the least-paid statistical modelers, and that the Wall Street speculators are about the most paid. Is at least that what you have found to be the case? [laughter]
Peter Brown
I think that Google has made a lot of money. Somebody at Google is doing something. Maybe it doesn’t go to the actual workers, I don’t know.
Stephen Della Pietra
When we started working in finance, there were 30 people in the whole company, [unintelligible] and with the company being so small, it was a really exciting time, because we were sort of, again, at the beginning of something. As with anything, when it gets more involved and bigger, it’s a little bit harder. So not quite as exciting in the same way I think.
Peter Brown
Okay, thanks a lot for having us!
Philip Resnik
Okay, thank you! [applause]
Chris Dyer
All right. So lunch until 3:00 and poster presenters, please be here.